
Notation des allocataires : l’indécence des pratiques de la CAF désormais indéniable
Catégorie :
Thèmes :
Lieux :
Après plus d’un an de mobilisation contre les pratiques de notation des allocataires de la CAF au côté des collectifs Stop Contrôles et Changer de Cap1, et après avoir détaillé le fonctionnement de l’algorithme de la CAF et son cadre politique, nous publions aujourd’hui le code source de cet algorithme de notation. Nous vous invitons aussi à consulter notre page de présentation sur l’utilisation d’algorithmes similaires au sein d’autres administrations.
Les détails techniques de l’algorithme (code, liste de variables et leurs pondérations) et de la méthodologie employée pour la construction de profils-types sont présentés dans cette annexe méthodologique.
Petit à petit, la lumière se fait sur un système de surveillance de masse particulièrement pernicieux2 : l’utilisation par la CAF d’un algorithme de notation des allocataires visant à prédire quel·les allocataires seraient (in)dignes de confiance et doivent être contrôlé·es.
Pour rappel, cet algorithme, construit à partir de l’analyse des centaines de données que la CAF détient sur chaque allocataire3, assigne un « score de suspicion » à chaque allocataire. Ce score, mis à jour chaque premier du mois, est compris entre zéro et un. Plus il est proche de un, plus l’algorithme juge qu’un·e allocataire est suspect·e : un contrôle est déclenché lorsqu’il se rapproche de sa valeur maximale4.
Lever l’opacité pour mettre fin à la bataille médiatique
Nos critiques portent tant sur la nature de cette surveillance prédictive aux accents dystopiques que sur le fait que l’algorithme cible délibérément les plus précaires5. Face à la montée de la contestation, les dirigeant·es de la CAF se sont réfugié·es derrière l’opacité entourant l’algorithme pour minimiser tant cet état de fait que leur responsabilité dans l’établissement d’une politique de contrôle délibérément discriminatoire. Un directeur de la CAF est allé jusqu’à avancer que « l’algorithme est neutre » et serait même « l’inverse d’une discrimination » puisque « nul ne peut expliquer pourquoi un dossier est ciblé »6.
C’est pourquoi nous avons bataillé de longs mois pour que la CAF nous donne accès au code source de l’algorithme, c’est à dire la « formule » utilisée par ses dirigeant·es pour noter les allocataires7. Nous espérons que sa publication mette un terme à ces contre-vérités afin, qu’enfin, puisse s’installer un débat autour des dérives politiques ayant amené une institution sociale à recourir à de telles pratiques.
L’algorithme de la honte…
La lecture du code source des deux modèles utilisés entre 2010 et 2018 — la CAF a refusé de nous transmettre la version actuelle de son algorithme — confirme tout d’abord l’ampleur du système de surveillance de détection des allocataires « suspect·es » mis en place par la CAF.
Situation familiale, professionnelle, financière, lieu de résidence, type et montants des prestations reçues, fréquence des connexions à l’espace web, délai depuis le dernier déplacement à l’accueil, nombre de mails échangés, délai depuis le dernier contrôle, nombre et types de déclarations : la liste de la quarantaine de paramètres pris en compte par l’algorithme, disponible ici, révèle le degré d’intrusion de la surveillance à l’oeuvre.
Elle s’attache à la fois aux données déclarées par un·e allocataire, à celles liées à la gestion de son dossier et celles concernant ses interactions, au sens large, avec la CAF. Chaque paramètre est enfin analysé selon un historique dont la durée est variable. Visant tant les allocataires que leurs proches, elle porte sur les plus de 32 millions de personnes, dont 13 millions d’enfants, vivant dans un foyer bénéficiant d’une prestation de la CAF.
Quant à la question du ciblage des plus précaires, la publication du code source vient donner la preuve définitive du caractère discriminant des critères retenus. Ainsi, parmi les variables augmentant le « score de suspicion », on trouve notamment :
- Le fait de disposer de revenus faibles,
- Le fait d’être au chômage,
- Le fait d’être allocataire du RSA,
- Le fait d’habiter dans un quartier « défavorisé »8,
- Le fait de consacrer une partie importante de ses revenus à son loyer,
- Le fait de ne pas avoir de travail ou de revenus stables.
Comble du cynisme, l’algorithme vise délibérément les personnes en situation de handicap : le fait de bénéficier de l’Allocation Adulte Handicapé (AAH) tout en travaillant est un des paramètres impactant le plus fortement, et à la hausse, le score d’un·e allocataire.
En un graphique
Bien entendu, ces facteurs sont corrélés et ne peuvent être considérés indépendamment les uns des autres. Il est ainsi probable qu’une personne aux faibles revenus ait connu des périodes de chômage ou bénéficie de minima sociaux etc…
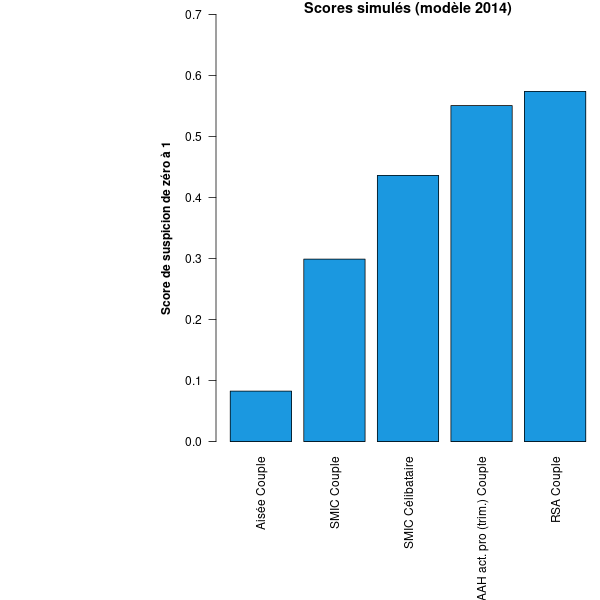
Disposant tant des paramètres que de leurs pondérations, nous avons pu construire différents profils-types d’allocataires pour lesquels nous avons calculé les scores de suspicion9. Entre les différents profils-types, nous avons seulement fait varier les paramètres liées à la situation professionnelle, aux revenus, aux prestations reçues, à la situation maritale ou de handicap.
Nous tenons à préciser que pour réaliser ces simulations, nous devons faire de nombreuses hypothèses dont il est parfois difficile de savoir si elles sont justes ou non. Ainsi, les scores simulés ci-dessous sont donnés à titre indicatif seulement. Nos résultats sont toutefois cohérents avec les analyses de Vincent Dubois basées sur des statistiques agrégées10. Dans un souci de transparence, nous détaillons leur construction — et ses limites — dans une annexe méthodologique11.
Les profils-types correspondent tous à des foyers comprenant deux enfants à charge et sont censés correspondre à :
- Une famille « aisée » aux revenus stables et élevés,
- Une famille « modeste » dont les deux parents gagnent le SMIC,
- Un parent isolé gagnant aussi le SMIC,
- Une famille dont les deux parents sont bénéficiaires des minima sociaux,
- Une famille dont un des parents est travailleur·se en situation de handicap : pour ce profil, nous simulons le score de la personne bénéficiant de l’AAH trimestrialisée.
Les résultats sont éclairants comme le montre le graphique ci-dessous. Les « scores de suspicion » des foyers les plus aisés sont bien plus faibles que ceux des foyers bénéficiant des minima sociaux ou de l’AAH trimestrialisée.
On observe également le ciblage des familles monoparentales, dont 80% sont des femmes12. Nos simulations indiquent que ce ciblage se fait indirectement — la CAF ayant peut-être jugé que l’inclusion d’une variable « mère célibataire » était trop risquée politiquement — en intégrant des variables comme le revenu total du foyer et le nombre de mois en activité cumulés sur un an des responsables du foyer, dont la nature vient mécaniquement défavoriser les foyers ne comprenant pas deux parents13.
Effets de seuil, discriminations et double peine
Il y a quelques mois, la CAF cherchait à minimiser la stigmatisation des plus précaires engendrée par son algorithme en expliquant que « les scores de risques les plus élevés » ne concernent pas « toujours les personnes les plus pauvres » car « le score de risque n’intègre pas comme seule donnée la situation financière »14. Nos analyses viennent démontrer à quel point ce raisonnement est fallacieux.
Ce que montre notre graphique c’est justement que les variables socio-économiques ont un poids prépondérant dans le calcul du score, désavantageant structurellement les personnes en situation de précarité. Ainsi, le risque d’être contrôlé suite à un événement considéré comme « facteur de risque » par l’algorithme – déménagement, séparation, décès – se révèle inexistant pour un allocataire aisé puisque son score est initialement proche de zéro. A l’inverse, pour un allocataire du RSA dont le score est déjà particulièrement élevé, le moindre de ces évènements risque de faire basculer son score au-delà du seuil à partir duquel un contrôle est déclenché.
Pire, la plupart des variables non financières sont en fait liées à des situations d’instabilité et d’écart à la norme – séparation récente, déménagements, changements de loyers multiples, modification répétée de l’activité professionnelle, perte de revenus, erreurs déclaratives, faible nombre de connexions web… – dont tout laisse à penser qu’elles sont elles-mêmes liées à des situations de précarité. A l’opposé de ce que veut faire croire la CAF, tout indique que cet algorithme fonctionne plutôt comme une « double peine » : il cible celles et et ceux qui, parmi les plus précaires, traversent une période particulièrement compliquée.
Clore le (faux) débat technique
La CAF ayant refusé de nous communiquer la version la plus récente de son algorithme, nous nous attendons à ce que ses dirigeant·es réagissent en avançant qu’iels disposent d’un nouveau modèle plus « équitable ». En anticipation, nous tenons à clarifier un point fondamental : il ne peut exister de modèle de l’algorithme qui ne cible pas les plus défavorisé·es, et plus largement celles et ceux qui s’écartent de la norme définie par ses concepteurs.
Comme nous l’expliquions ici de manière détaillée, si l’algorithme de la CAF a été promu au nom de la « lutte contre la fraude », il a en réalité été conçu pour détecter les « indus » (trop-perçus). Ce choix a été fait pour des questions de rentabilité : les indus sont plus nombreux et plus faciles à détecter que des cas de fraude dont la caractérisation nécessite, en théorie, de prouver une intention15.
Or, ces indus ont pour cause principale des erreurs déclaratives involontaires, dont toutes les études montrent qu’elles se concentrent principalement sur les personnes aux minima sociaux et de manière plus générale sur les allocataires en difficulté. Cette concentration s’explique d’abord par le fait que ces prestations sont encadrées par des règles complexes — fruit des politiques successives de « lutte contre l’assistanat » — multipliant le risque d’erreurs possibles. Pour reprendre les termes d’un directeur de la lutte contre la fraude de la CNAF : « ce sont les prestations sociales elles-mêmes qui génèrent le risque […] ceci est d’autant plus vrai pour les prestations liées à la précarité […], très tributaires de la situation familiale, financière et professionnelle des bénéficiaires. »16.
Nul besoin donc de connaître le détail de la formule de l’algorithme pour prédire quelles populations seront ciblées car c’est l’objectif politique de l’algorithme — détecter les trop-perçus — qui le détermine. C’est pourquoi laisser s’installer un débat autour de l’inclusion de telle ou telle variable est un jeu de dupes statistiques. La CAF pourra toujours substituer à une variable jugée politiquement « sensible » d’autres critères jugés « acceptables » permettant d’aboutir au même résultat, comme elle semble déjà le faire pour les mères célibataires17.
Logiques policières, logiques gestionnaires
Dire cela, c’est enfin dépasser le débat technique et reconnaître que cet algorithme n’est que le reflet de la diffusion de logiques gestionnaires et policières au sein de nos administrations sociales au nom des politiques de « lutte contre la fraude ».
C’est en transformant les allocataires en « assisté·es », puis en risques pour la survie de notre système social que le discours de « lutte contre l’assistanat » a fait de leur contrôle un impératif de « bonne gestion »18. Qu’importe que toutes les estimations montrent que la « fraude sociale » est marginale et que c’est au contraire le non-recours aux aides qui se révèle être un phénomène massif.
Devenu objectif institutionnel, le contrôle doit être rationalisé. Le numérique devient alors l’outil privilégié de « la lutte contre la fraude sociale » par la capacité qu’il offre aux dirigeant·es de répondre aux injonctions de résultats tout en offrant un alibi technique quant aux pratiques de discrimination généralisée que leur tenue impose.
Ces logiques sont saillantes dans la réponse écrite par la CAF pour s’opposer à la transmission du code de son algorithme, avant d’y être contrainte par la Commission d’Accès aux Documents Administratifs (CADA). Elle assume ouvertement un discours policier en avançant comme principal argument que cette communication consisterait en une « atteinte à la sécurité publique » car « en identifiant les critères constituant des facteurs de ciblage, des fraudeurs pourraient organiser et monter des dossiers frauduleux ».
Enfin, un chiffre transmis dans la même réponse témoigne de l’emballement gestionnaire à l’œuvre et vient souligner la disproportion entre les moyens techniques déployés et les enjeux financiers. L’algorithme est entraîné pour détecter des trop-perçus s’élevant à 600 euros sur deux ans. Soit donc, 32 millions d’intimités violées par un algorithme à la recherche de… 25 euros par mois.
Lutter
L’Assurance maladie, l’Assurance vieillesse, les Mutualités Sociales Agricoles ou dans une moindre mesure Pôle Emploi : toutes utilisent ou développent des algorithmes en tout point similaires. À l’heure où ces pratiques de notation se généralisent, il apparaît nécessaire de penser une lutte à grande échelle.
C’est pourquoi nous avons décidé de faire de ces pratiques de contrôle algorithmique une priorité pour l’année à venir. Vous trouverez ici notre page dédiée à ce sujet, que nous alimenterons régulièrement.
______________
References
References ↑1 Vous pouvez les contacter à stop.controles@protonmail.com et contact@changerdecap.net.
↑2 La CAF n’est pas la seule administration à utiliser ce type d’algorithmes, mais elle fut la première à le faire. Nous reviendrons bientôt sur une vision plus globale de l’utilisation de ce type d’algorithmes par les administrations sociales dans leur ensemble.
↑3 Si l’algorithme lui-même n’utilise que quelques dizaines de variables pour calculer la note des allocataires, celles-ci sont sélectionnées après une phase dite d’« entraînement » mobilisant plus de 1000 informations par allocataire. Pour des détails techniques voir l’article de Pierre Collinet « Le datamining dans les caf : une réalité, des perspectives », écrit en 2013 et disponible ici.
↑4 Les contrôles à la CAF sont de trois types. Les contrôles automatisés sont des procédures de vérification des déclarations des allocataires (revenus, situation professionnelle..), organisés via à l’interconnexion des fichiers administratifs (impôts, pôle emploi…). Ce sont de loin les plus nombreux. Les contrôles sur pièces consistent en la demande de pièces justificatives supplémentaires à l’allocataire. Enfin les contrôles sur place sont les moins nombreux mais les plus intrusifs. Réalisé par un.e contrôleur.se de la CAF, ils consistent en un contrôle approfondi de la situation de l’allocataire. Ce sont ces derniers qui sont aujourd’hui en très grande majorité déclenchés par l’algorithme suite à une dégradation de la note d’un allocataire (Voir Vincent Dubois, « Contrôler les assistés », p.258).
↑5 Voir avant tout le livre de Vincent Dubois publié en 2021. « Contrôler les assistés. Genèses et usage d’un mot d’ordre ». Sur le sur-contrôle des populations les plus précaires, voir le chapitre 10. Sur l’histoire politique de la « lutte contre l’assistanat », et le rôle majeur que joua en France Nicolas Sarkozy, voir le chapitre 2. Sur l’évolution des politiques de contrôles, leur centralisation suite à l’introduction de l’algorithme et la définition des cibles, voir pages 177 et 258. Sur la contestation des plans nationaux de ciblages par les directeurs de CAF locales, voir page 250. Voir aussi Dubois V., Paris M., Weill P-Edouard., 2016, Politique de contrôle et lutte contre la fraude dans la branche famille, Cnaf, Dossier d’études, n°183 disponible ici
↑6 Extrait de la réponse d’un directeur de la CAF aux critiques opposées par le Défenseur des Droits à l’utilisation de cet algorithme.
↑7 La CAF nous avait initialement communiqué un code source « caviardé » dans lequel la quasi-totalité des noms de variables étaient masqués. Nous avons finalement obtenu le code de deux versions de l’algorithme. La première a été utilisée entre 2010 et 2014. La seconde entre 2014 et 2018. Six variables ont tout de même été occultées du modèle « 2010 » et 3 du modèle « 2014 ».
↑8 Concernant la variable liée au lieu de résidence, cette dernière fait a priori partie des variables masquées dans le code reçu. Elle est toute fois mentionnées dans la réponse de la CAF à la CADA, ce pourquoi il nous paraît raisonnable de l’inclure ici. Voir notre annexe méthodologique pour une discussion détaillée de la formule.
↑9 Pour ce faire, nous avons simulé les données nécessaires – une trentaine de variables – pour chaque « profil-type » puis utilisé l’algorithme pour calculer leur note. Pour plus de détails, voir notre annexe méthodologique.
↑10 Le sur-ciblage des personnes en situation de handicap – bénéficiaires de l’AAH – ne concerne que celles disposant d’un travail. C’est ainsi que ces résultats sont compatibles avec les analyses du chapitre 10 du livre Contrôler les assistés de Vincent Dubois qui regroupent l’ensemble des personnes en situation de handicap. Voir notre annexe méthodologique pour une discussion détaillée de ce point.
↑11 Voir notamment une méthodologie alternative utilisée par LightHouse Reports dans son article sur Rotterdam pour lequel les journalistes disposaient non seulement de la formule mais aussi de données sur les personnes visées. Elle est disponible ici.
↑12 Voir la note de l’Insee disponible ici.
↑13 A revenus égaux, un parent seul gagne moins que deux parents. Quant au nombre de mois d’activité sur une année, il ne dépassera jamais 12 par an pour une famille monoparentale mais peut aller jusqu’à 24 pour un couple. Ce ciblage est particulièrement fort dans les mois qui suivent une séparation, ce type d’évènement dégradant fortement le score d’un·e allocataire. Voir nos analyses additionnelles en annexe méthodologique.
↑14 C’est ce qu’elle a déjà fait dans son « Vrai/Faux » sur le datamining où elle expliquait que « les scores de risques les plus élevés » ne concernent pas « toujours les personnes les plus pauvres » car « le score de risque n’intègre pas comme seule donnée la situation financière ».
↑15 Les témoignages collectés par Stop Contrôles ou Changer de Cap montrent que la nécessité de prouver l’intentionnalité pour qualifier un indu de fraude – dont les conséquences pour un•e allocataire sont plus lourdes – est très régulièrement bafouée.
↑16 Voir Daniel Buchet. 2006. « Du contrôle des risques à la maitrise des risques ». Disponible ici.
↑17 Il serait ainsi relativement facile pour la CAF de supprimer la référence directe aux minima sociaux ou à l’AAH dans son algorithme en se limitant à l’utilisation de la variable « faits générateurs trimestriels ». Cette dernière ne concerne que les allocations nécessitant une déclaration de ressources trimestrielles : AAH trimestrielle, APL, RSA et prime d’activité. S’agissant du ciblage des allocataires du RSA et de l’AAH, la CAF pourrait ainsi prétendre, sans trop perdre de précision, avoir modifié son algorithme en ne retenant dans le calcul que cette variable « faits générateurs trimestriels » tout en continuant à cibler les personnes aux minima sociaux.
↑18 Voir avant tout le livre de Vincent Dubois publié en 2021. « Contrôler les assistés. Genèses et usage d’un mot d’ordre ». Sur le sur-contrôle des populations les plus précaires, voir le chapitre 10. Sur l’histoire politique de la « lutte contre l’assistanat », et le rôle majeur que joua en France Nicolas Sarkozy, voir le chapitre 2. Sur l’évolution des politiques de contrôles, leur centralisation suite à l’introduction de l’algorithme et la définition des cibles, voir pages 177 et 258. Sur la contestation des plans nationaux de ciblages par les directeurs de CAF locales, voir page 250.
________
Galerie

{kind=link}
Commentaires
Les commentaires sont modérés a posteriori.Laisser un commentaire